给你一个数组 nums 。数组「动态和」的计算公式为:runningSum[i] = sum(nums[0]…nums[i]) 。
请返回 nums 的动态和。
示例 1:
输入:nums = [1,2,3,4]
输出:[1,3,6,10]
解释:动态和计算过程为 [1, 1+2, 1+2+3, 1+2+3+4] 。
示例 2:
输入:nums = [1,1,1,1,1]
输出:[1,2,3,4,5]
解释:动态和计算过程为 [1, 1+1, 1+1+1, 1+1+1+1, 1+1+1+1+1] 。
示例 3:
输入:nums = [3,1,2,10,1]
输出:[3,4,6,16,17]
方法二:动态规划 时间复杂度O(n)
动态求和公式:temp[i] = temp[i-1] + nums[i];
1 | class Solution { |
1512. 好数对的数目
给你一个整数数组 nums 。
如果一组数字 (i,j) 满足 nums[i] == nums[j] 且 i < j ,就可以认为这是一组 好数对 。
返回好数对的数目。
示例 1:
输入:nums = [1,2,3,1,1,3]
输出:4
解释:有 4 组好数对,分别是 (0,3), (0,4), (3,4), (2,5) ,下标从 0 开始
示例 2:
输入:nums = [1,1,1,1]
输出:6
解释:数组中的每组数字都是好数对
示例 3:
输入:nums = [1,2,3]
输出:0
方法一:暴力解法,时间复杂度:O(n^2)
1 | class Solution { |
方法二:时间复杂度为O(n)
好数对满足2个条件:
- nums[i] == nums[j]
- i < j
假如输入[1,1,1,1]
我们从前往后遍历的时候,好数对的数量为:3:[0,1],[0,2],[0,3]
2:[1,2],[1,3]
1:[2,3]
这里我们举的例子是[1,1,1,1],如果我们的例子是[2,1,1,1,1,4]结果也是一样的
所以当我们从前往后遍历的时候,我们把数值存放在temp数组中,实际上计算的结果顺序是从后往前的,
即1 + 2 + 3 = 6;
这个结果其实跟我们正常理解的3 + 2 + 1 = 6的结果是一致的
1 | class Solution { |
1 | class Solution { |
1431. 拥有最多糖果的孩子
给你一个数组 candies 和一个整数 extraCandies ,其中 candies[i] 代表第 i 个孩子拥有的糖果数目。
对每一个孩子,检查是否存在一种方案,将额外的 extraCandies 个糖果分配给孩子们之后,此孩子有 最多 的糖果。注意,允许有多个孩子同时拥有 最多 的糖果数目。
示例 1:
输入:candies = [2,3,5,1,3], extraCandies = 3
输出:[true,true,true,false,true]
解释:
孩子 1 有 2 个糖果,如果他得到所有额外的糖果(3个),那么他总共有 5 个糖果,他将成为拥有最多糖果的孩子。
孩子 2 有 3 个糖果,如果他得到至少 2 个额外糖果,那么他将成为拥有最多糖果的孩子。
孩子 3 有 5 个糖果,他已经是拥有最多糖果的孩子。
孩子 4 有 1 个糖果,即使他得到所有额外的糖果,他也只有 4 个糖果,无法成为拥有糖果最多的孩子。
孩子 5 有 3 个糖果,如果他得到至少 2 个额外糖果,那么他将成为拥有最多糖果的孩子。
示例 2:
输入:candies = [4,2,1,1,2], extraCandies = 1
输出:[true,false,false,false,false]
解释:只有 1 个额外糖果,所以不管额外糖果给谁,只有孩子 1 可以成为拥有糖果最多的孩子。
示例 3:
输入:candies = [12,1,12], extraCandies = 10
输出:[true,false,true]
1 | class Solution { |
1470. 重新排列数组
给你一个数组 nums ,数组中有 2n 个元素,按 [x1,x2,…,xn,y1,y2,…,yn] 的格式排列。
请你将数组按 [x1,y1,x2,y2,…,xn,yn] 格式重新排列,返回重排后的数组。
示例 1:
输入:nums = [2,5,1,3,4,7], n = 3
输出:[2,3,5,4,1,7]
解释:由于 x1=2, x2=5, x3=1, y1=3, y2=4, y3=7 ,所以答案为 [2,3,5,4,1,7]
示例 2:
输入:nums = [1,2,3,4,4,3,2,1], n = 4
输出:[1,4,2,3,3,2,4,1]
示例 3:
输入:nums = [1,1,2,2], n = 2
输出:[1,2,1,2]
1 | class Solution { |
1486. 数组异或操作
给你两个整数,n 和 start 。
数组 nums 定义为:nums[i] = start + 2*i(下标从 0 开始)且 n == nums.length 。
请返回 nums 中所有元素按位异或(XOR)后得到的结果。
示例 1:
输入:n = 5, start = 0
输出:8
解释:数组 nums 为 [0, 2, 4, 6, 8],其中 (0 ^ 2 ^ 4 ^ 6 ^ 8) = 8 。
“^” 为按位异或 XOR 运算符。
示例 2:
输入:n = 4, start = 3
输出:8
解释:数组 nums 为 [3, 5, 7, 9],其中 (3 ^ 5 ^ 7 ^ 9) = 8.
示例 3:
输入:n = 1, start = 7
输出:7
示例 4:
输入:n = 10, start = 5
输出:2
暴力法
1 | class Solution { |
复杂度分析:
- 时间复杂度:O(n), n是数组的长度
- 空间复杂度:O(1)
位运算(利用 XOR 的特性)
XOR 有很多有用的特性:
x \oplus x = 0x⊕x=0
0 \oplus x = x0⊕x=x
2x \oplus (2x+1) = 12x⊕(2x+1)=1
我们来看看题目的要求:
start \oplus start + 2 \oplus start + 4 … \oplus start + 2n-2start⊕start+2⊕start+4…⊕start+2n−2
你会发现题目的要求和上面我们列举的特性 3 很像,只是异或元素每次都是递增 2。
因此,我们可以对题目进行一次处理,也就是对所有异或元素右移一位,得到 start/2 \oplus start/2 + 1 \oplus start/2 + 2 … \oplus start/2 + n-1start/2⊕start/2+1⊕start/2+2…⊕start/2+n−1
相当于我们将最终结果向右移动了一位,那么最后一位是什么呢?
我们会发现最后一位是由 startstart 和 数组长度 nn 决定的。这是由于 2,4,…2,4,… 这些转换成二进制后最后一位都是 0。
因此如果 start 是偶数,那么最后一位肯定是 0.
如果 start 是奇数,但是 nn 是偶数,这里我们使用特性 1,得到最后一位也是 0.
其他情况下,最后一位是 1.
那么 start/2 \oplus start/2 + 1 \oplus start/2 + 2 … \oplus start/2 + n-1start/2⊕start/2+1⊕start/2+2…⊕start/2+n−1 该怎么计算呢?
我们可以按照特性 3 来补全:
如果 start/2start/2 是偶数,我们只需要看 nn 是否是偶数即可:
如果 nn 是偶数,该公式结果就是 n/2n/2 个 1 进行异或。也就是 (n/2) & 1(n/2)&1
如果 nn 是奇数,该公式结果就是 ((n/2) & 1) \oplus (start/2+n-1)((n/2)&1)⊕(start/2+n−1)
如果 start/2start/2 是奇数,那么我们可以在前面补充 (start/2-1) \oplus (start/2-1)(start/2−1)⊕(start/2−1),就回到了情况 1.
1 | /** |
复杂度分析:
- 时间复杂度:O(1), n是数组的长度
- 空间复杂度:O(1)
剑指 Offer 58 - II. 左旋转字符串
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串”abcdefg”和数字2,该函数将返回左旋转两位得到的结果”cdefgab”。
示例 1:
输入: s = “abcdefg”, k = 2
输出: “cdefgab”
1 | class Solution { |
若面试规定不允许使用 切片函数 ,则使用此方法。
算法流程:
新建一个 list(Python)、StringBuilder(Java) ,记为 resres ;
先向 resres 添加 “第 n + 1n+1 位至末位的字符” ;
再向 resres 添加 “首位至第 nn 位的字符” ;
将 resres 转化为字符串并返回。
复杂度分析:
时间复杂度 O(N)O(N) : 线性遍历 ss 并添加,使用线性时间;
空间复杂度 O(N)O(N) : 新建的辅助 resres 使用 O(N)O(N) 大小的额外空间。
方法三:字符串遍历拼接
若规定 Python 不能使用 join() 函数,或规定 Java 只能用 String ,则使用此方法。
此方法与 方法二 思路一致,区别是使用字符串代替列表。
复杂度分析:
时间复杂度 O(N)O(N) : 线性遍历 ss 并添加,使用线性时间;
空间复杂度 O(N)O(N) : 假设循环过程中内存会被及时回收,内存中至少同时存在长度为 NN 和 N-1N−1 的两个字符串(新建长度为 NN 的 resres 需要使用前一个长度 N-1N−1 的 resres ),因此至少使用 O(N)O(N) 的额外空间。
1 | class Solution { |
1. 两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
1 | class Solution { |
线性表的两种存储结构各有哪些优缺点
1 | 线性表具有两种存储结构即顺序存储结构和链接存储结构。 |
1025. 除数博弈
爱丽丝和鲍勃一起玩游戏,他们轮流行动。爱丽丝先手开局。
最初,黑板上有一个数字 N 。在每个玩家的回合,玩家需要执行以下操作:
选出任一 x,满足 0 < x < N 且 N % x == 0 。
用 N - x 替换黑板上的数字 N 。
如果玩家无法执行这些操作,就会输掉游戏。
只有在爱丽丝在游戏中取得胜利时才返回 True,否则返回 false。假设两个玩家都以最佳状态参与游戏。
题目解析
对于这种博弈类的题目,如果没有思路的话我们不妨多举几个例子,尝试着从中找寻规律。
假设 N = 1,爱丽丝没得选择,直接失败,即 鲍勃获胜;
假设 N = 2,爱丽丝有选择,她可以选择 x = 1,鲍勃面对的就是 N = 2 - 1 = 1,无法操作,爱丽丝获胜;
假设 N = 3,爱丽丝只能选择 x = 1,因为选 x = 2 不满足 3 % 2 = 0,鲍勃面对的就是 N = 3 - 1 = 2,参考上面 N = 2 的情形,此时鲍勃为 N = 2 的先手,鲍勃获胜;
假设 N = 4,爱丽丝可以选择 x = 1 来使鲍勃遇到 N = 3 的情况,爱丽丝获胜;
貌似有个规律:N 为奇数时, 鲍勃获胜;N 为偶数时, 爱丽丝获胜。
是这样吗?
是的。
事实上,无论 N 为多大,最终都是在 N = 2 这个临界点结束的。谁最后面对的是 N = 2 的情形,谁就能获胜(这句话不太理解的话,仔细看看 N = 2、N = 3 这两种情形)。
接下来,我们得知道一个数学小知识:奇数的因子(约数)只能是奇数,偶数的因子(约数)可以是奇数或偶数。
千万不要忽略 1 也是因子!
爱丽丝是游戏开始时的先手。
当她面对的 N 为偶数时,她 一定可以 选到一个 N 的奇数因子 x(比如 1 ),将 N - x 这个奇数传给鲍勃;用 N - x 替换黑板上的数字 N ,鲍勃面对的就是奇数 N,只能选择 N 的奇数因子 x,奇数 - 奇数 = 偶数,此时传给爱丽丝的又是偶数。这样轮换下去爱丽丝会遇到 N = 2 的情形,然后获胜;
当爱丽丝遇到的 N 是奇数时,只能传给鲍勃偶数或无法操作 (N = 1) ,无法获胜。
1 | public boolean divisorGame(int N) { |
461. 汉明距离
两个整数之间的汉明距离指的是这两个数字对应二进制位不同的位置的数目。
给出两个整数 x 和 y,计算它们之间的汉明距离。
注意:
0 ≤ x, y < 231.
示例:
输入: x = 1, y = 4
输出: 2
解释:
1 (0 0 0 1)
4 (0 1 0 0)
↑ ↑
上面的箭头指出了对应二进制位不同的位置。
1 | public int hammingDistance(int x, int y) { |
思路
汉明距离广泛应用于多个领域。在编码理论中用于错误检测,在信息论中量化字符串之间的差异。
两个整数之间的汉明距离是对应位置上数字不同的位数。
根据以上定义,提出一种 XOR 的位运算,当且仅当输入位不同时输出为 1。
计算 x 和 y 之间的汉明距离,可以先计算 x XOR y,然后统计结果中等于 1 的位数。
现在,原始问题转换为位计数问题。位计数有多种思路,将在下面的方法中介绍。
方法一:内置位计数功能
思路
大多数编程语言中,都存在各种内置计算等于 1 的位数函数。如果这是一个项目中的问题,应该直接使用内置函数,而不是重复造轮子。
但这是一个力扣问题,有人会认为使用内置函数就好像使用 使用 LinkedList 实现 LinkedList。对此,我们完全赞同。因此后面会有手工实现的位计数算法。
PythonJava
1 | class Solution: |
复杂度分析
时间复杂度:\mathcal{O}(1)O(1)。
该算法有两个操作。计算 XOR 花费恒定时间。
调用内置的 bitCount 函数。最坏情况下,该函数复杂度为 \mathcal{O}(k)O(k),其中 kk 是整数的位数。在 Python 和 Java 中 Integer 是固定长度的。因此该算法复杂度恒定,与输入大小无关。
空间复杂度:\mathcal{O}(1)O(1),使用恒定大小的空间保存 XOR 的结果。
假设内置函数也使用恒定空间。
方法二:移位
思路
为了计算等于 1 的位数,可以将每个位移动到最左侧或最右侧,然后检查该位是否为 1。
更准确的说,应该进行逻辑移位,移入零替换丢弃的位。
这里采用右移位,每个位置都会被移动到最右边。移位后检查最右位的位是否为 1 即可。检查最右位是否为 1,可以使用取模运算(i % 2)或者 AND 操作(i & 1),这两个操作都会屏蔽最右位以外的其他位。
PythonJava
1 | class Solution(object): |
复杂度分析
时间复杂度:\mathcal{O}(1)O(1),在 Python 和 Java 中 Integer 的大小是固定的,处理时间也是固定的。 32 位整数需要 32 次迭代。
空间复杂度:\mathcal{O}(1)O(1),使用恒定大小的空间。
方法三:布赖恩·克尼根算法
思路
方法二是逐位移动,逐位比较边缘位置是否为 1。寻找一种更快的方法找出等于 1 的位数。
是否可以像人类直观的计数比特为 1 的位数,跳过两个 1 之间的 0。例如:10001000。
上面例子中,遇到最右边的 1 后,如果可以跳过中间的 0,直接跳到下一个 1,效率会高很多。
这是布赖恩·克尼根位计数算法的基本思想。该算法使用特定比特位和算术运算移除等于 1 的最右比特位。
当我们在 number 和 number-1 上做 AND 位运算时,原数字 number 的最右边等于 1 的比特会被移除。
基于以上思路,通过 2 次迭代就可以知道 10001000 中 1 的位数,而不需要 8 次。
PythonJava
1 | class Solution: |
注意:该算法发布在 1988 年 《C 语言编程第二版》的练习中(由 Brian W. Kernighan 和 Dennis M. Ritchie 编写),但是 Donald Knuth 在 2006 年 4 月 19 日指出,该方法第一次是由 Peter Wegner 在 1960 年的 CACM3 上出版。顺便说一句,可以在上述书籍中找到更多位操作的技巧。
复杂度分析
时间复杂度:\mathcal{O}(1)O(1)。
与移位方法相似,由于整数的位数恒定,因此具有恒定的时间复杂度。
但是该方法需要的迭代操作更少。
空间复杂度:\mathcal{O}(1)O(1),与输入无关,使用恒定大小的空间。
方法一:二分查找
思路与算法
假设题意是叫你在排序数组中寻找是否存在一个目标值,那么训练有素的读者肯定立马就能想到利用二分法在 O(\log n)O(logn) 的时间内找到是否存在目标值。但这题还多了个额外的条件,即如果不存在数组中的时候需要返回按顺序插入的位置,那我们还能用二分法么?答案是可以的,我们只需要稍作修改即可。
考虑这个插入的位置 \textit{pos}pos,它成立的条件为:
\textit{nums}[pos-1]<\textit{target}\le \textit{nums}[pos]
nums[pos−1]<target≤nums[pos]
其中 \textit{nums}nums 代表排序数组。由于如果存在这个目标值,我们返回的索引也是 \textit{pos}pos,因此我们可以将两个条件合并得出最后的目标:「在一个有序数组中找第一个大于等于 \textit{target}target 的下标」。
问题转化到这里,直接套用二分法即可,即不断用二分法逼近查找第一个大于等于 \textit{target}target 的下标 。下文给出的代码是笔者习惯的二分写法,\textit{ans}ans 初值设置为数组长度可以省略边界条件的判断,因为存在一种情况是 \textit{target}target 大于数组中的所有数,此时需要插入到数组长度的位置。
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/search-insert-position/solution/sou-suo-cha-ru-wei-zhi-by-leetcode-solution/
1 | class Solution { |
复杂度分析
时间复杂度:O(\log n)O(logn),其中 nn 为数组的长度。二分查找所需的时间复杂度为 O(\log n)O(logn)。
空间复杂度:O(1)O(1)。我们只需要常数空间存放若干变量。
42. 接雨水
难度困难1491收藏分享切换为英文关注反馈
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。

上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 感谢 Marcos 贡献此图。
示例:
1 | 输入: [0,1,0,2,1,0,1,3,2,1,2,1] |
1 | public int trap(int[] height) { |
104. 二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
1 | /** |
9. 回文数
判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
示例 1:
1 | 输入: 121 |
方法一:反转一半数字
思路
映入脑海的第一个想法是将数字转换为字符串,并检查字符串是否为回文。但是,这需要额外的非常量空间来创建问题描述中所不允许的字符串。
第二个想法是将数字本身反转,然后将反转后的数字与原始数字进行比较,如果它们是相同的,那么这个数字就是回文。
但是,如果反转后的数字大于 \text{int.MAX}int.MAX,我们将遇到整数溢出问题。
按照第二个想法,为了避免数字反转可能导致的溢出问题,为什么不考虑只反转 \text{int}int 数字的一半?毕竟,如果该数字是回文,其后半部分反转后应该与原始数字的前半部分相同。
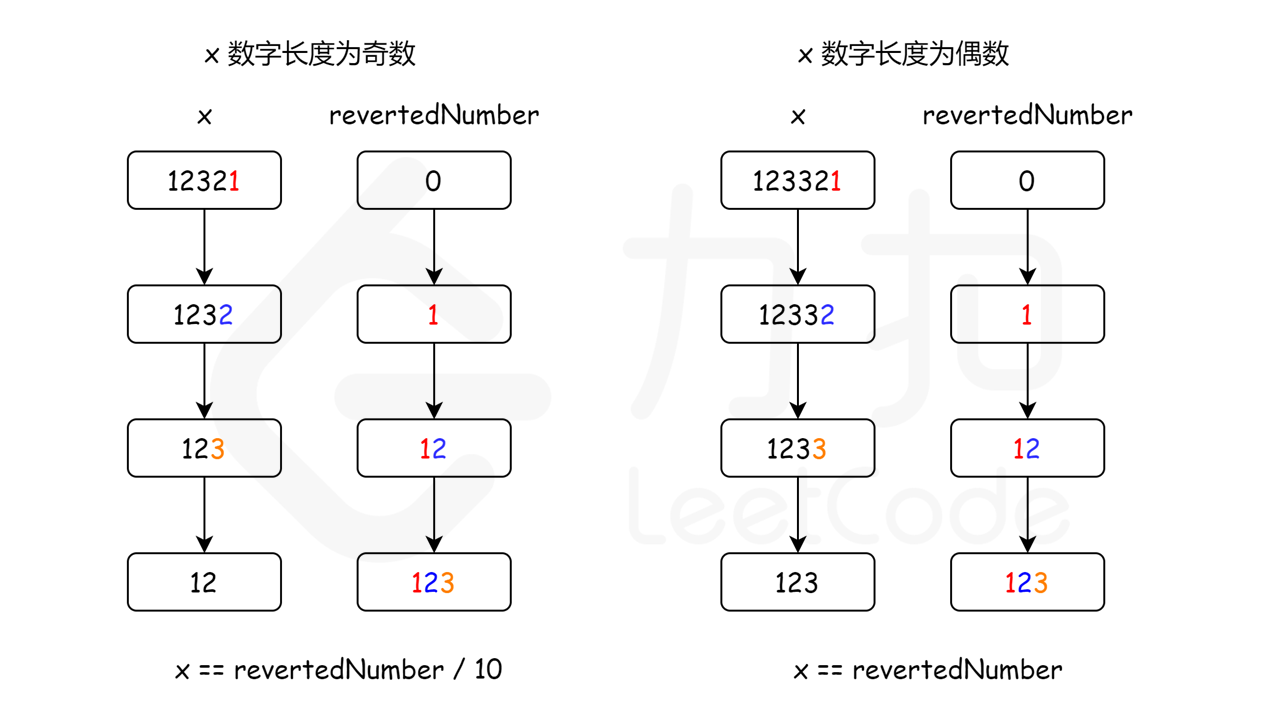
例如,输入 1221,我们可以将数字 “1221” 的后半部分从 “21” 反转为 “12”,并将其与前半部分 “12” 进行比较,因为二者相同,我们得知数字 1221 是回文。
算法
首先,我们应该处理一些临界情况。所有负数都不可能是回文,例如:-123 不是回文,因为 - 不等于 3。所以我们可以对所有负数返回 false。除了 0 以外,所有个位是 0 的数字不可能是回文,因为最高位不等于 0。所以我们可以对所有大于 0 且个位是 0 的数字返回 false。
现在,让我们来考虑如何反转后半部分的数字。
对于数字 1221,如果执行 1221 % 10,我们将得到最后一位数字 1,要得到倒数第二位数字,我们可以先通过除以 10 把最后一位数字从 1221 中移除,1221 / 10 = 122,再求出上一步结果除以 10 的余数,122 % 10 = 2,就可以得到倒数第二位数字。如果我们把最后一位数字乘以 10,再加上倒数第二位数字,1 * 10 + 2 = 12,就得到了我们想要的反转后的数字。如果继续这个过程,我们将得到更多位数的反转数字。
现在的问题是,我们如何知道反转数字的位数已经达到原始数字位数的一半?
由于整个过程我们不断将原始数字除以 10,然后给反转后的数字乘上 10,所以,当原始数字小于或等于反转后的数字时,就意味着我们已经处理了一半位数的数字了。
1 |