ElasticSearch的使用
.jpg)
ElasticSearch
Windows下安装elasticsearch
在安装Elasticsearch引擎之前,必须安装ES需要的软件环境
注意:安装elasticsearch7.4运行需要jdk11及以上
elasticsearch与jdk有依赖关系
配置环境变量
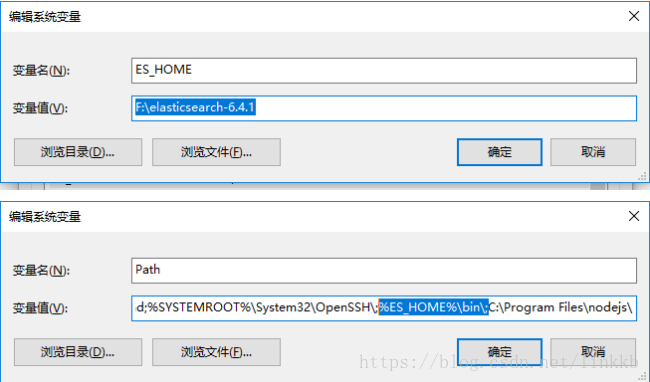
- 测试运行
点击/bin目录下的elasticsearch.bat开始安装
安装elasticsearch的head插件
es5以上版本安装head需要安装node和grunt(之前的直接用plugin命令即可安装)
(一)从地址:https://nodejs.org/en/download/ 下载相应系统的msi,双击安装。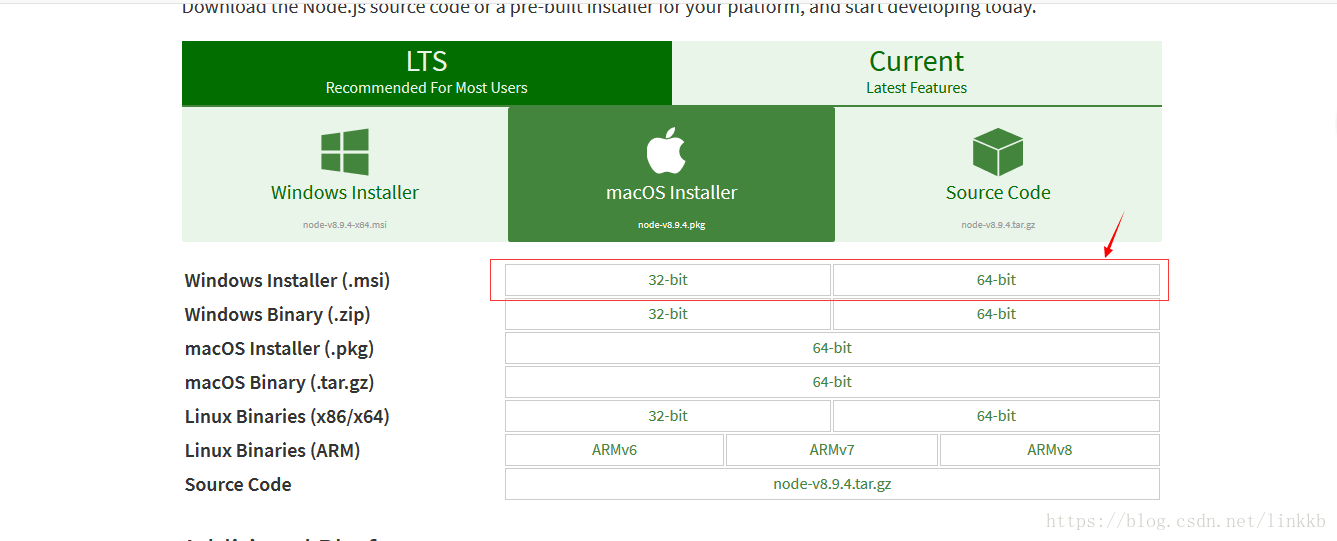
(二)安装完成用cmd进入安装目录执行 node -v可查看版本号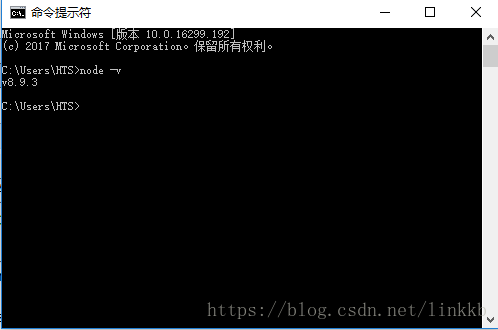
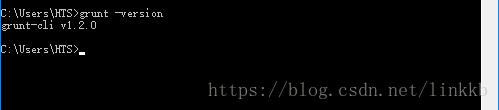
(三)执行 npm install -g grunt-cli 安装grunt ,安装完成后执行grunt -version查看是否安装成功,会显示安装的版本号
(四)开始安装head
① 进入安装目录下的config目录,修改elasticsearch.yml文件.在文件的末尾加入以下代码
http.cors.enabled: true
http.cors.allow-origin: “*”
node.master: true
node.data: true
然后去掉network.host: 192.168.0.1的注释并改为network.host: 0.0.0.0,去掉cluster.name;node.name;http.port的注释(也就是去掉#)
elasticsearch-7.1.1 版本 yml文件需要这个 cluster.initial_master_nodes: [“node-1”]
②双击elasticsearch.bat重启es
③在https://github.com/mobz/elasticsearch-head中下载head插件,选择下载zip
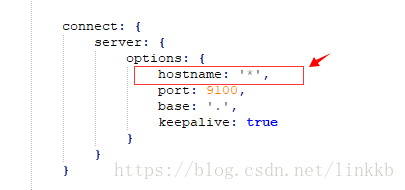
④解压到指定文件夹下,G:\elasticsearch-6.4.1\elasticsearch-head-master 进入该文件夹,修改G:\elasticsearch-6.4.1\elasticsearch-head-master\Gruntfile.js 在对应的位置加上hostname:’*’
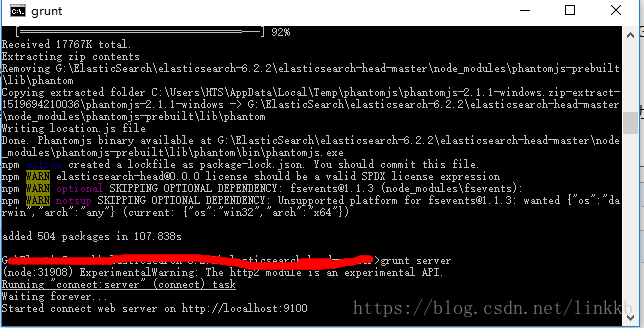
⑤在G:\elasticsearch-6.6.2\elasticsearch-head-master 下执行npm install 安装完成后执行grunt server 或者npm run start 运行head插件,如果不成功重新安装grunt。成功如下
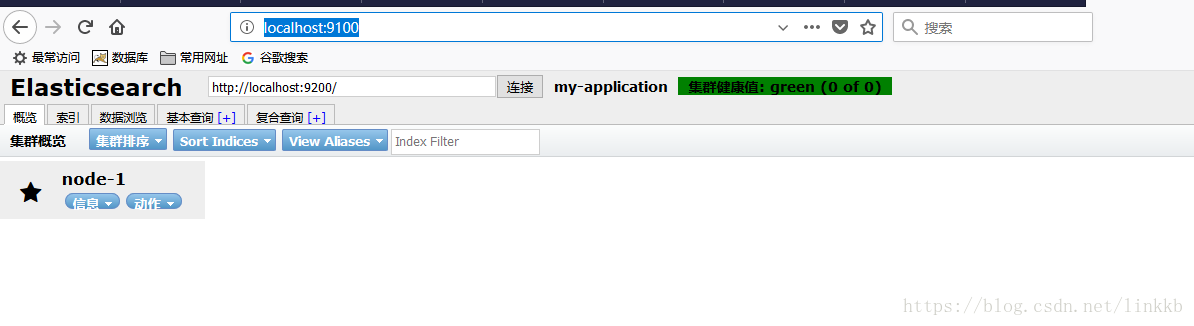
⑥浏览器下访问http://localhost:9100/
整合springboot
参考博客 https://segmentfault.com/a/1190000018625101?utm_source=tag-newest
https://blog.csdn.net/chen_2890/article/details/83895646
- properties
1 | =elasticsearch |
- pom.xml
1 | <dependency> |
- ```java
}/** * * @Description:matchQuery *@Author: https://blog.csdn.net/chen_2890 */ @Test public void testMathQuery(){ // 创建对象 NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // 在queryBuilder对象中自定义查询 //matchQuery:底层就是使用的termQuery queryBuilder.withQuery(QueryBuilders.matchQuery("title","坚果")); //查询,search 默认就是分页查找 Page<Item> page = this.itemRepository.search(queryBuilder.build()); //获取数据 long totalElements = page.getTotalElements(); System.out.println("获取的总条数:"+totalElements); for(Item item:page){ System.out.println(item); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
```java
/**
* @Description:
* termQuery:功能更强大,除了匹配字符串以外,还可以匹配
* int/long/double/float/....
* @Author: https://blog.csdn.net/chen_2890
*/
@Test
public void testTermQuery(){
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
builder.withQuery(QueryBuilders.termQuery("price",998.0));
// 查找
Page<Item> page = this.itemRepository.search(builder.build());
for(Item item:page){
System.out.println(item);
}
}
1 | /** |
1 | /** |
Elasticsearch-基础介绍及索引原理分析
最近在参与一个基于Elasticsearch作为底层数据框架提供大数据量(亿级)的实时统计查询的方案设计工作,花了些时间学习Elasticsearch的基础理论知识,整理了一下,希望能对Elasticsearch感兴趣/想了解的同学有所帮助。 同时也希望有发现内容不正确或者有疑问的地方,望指明,一起探讨,学习,进步。
介绍
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
1 | { |
用Mysql这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表: